Cycles 誕生から10年、そして Cycles X
投稿日時 2021年04月24日 | カテゴリ: 技術・開発関連
|
元記事:Cycles X - Blender Developers Blog
brechet 氏による記事の翻訳です。
今日(4月23日)でちょうど Cycles が発表されて10年経ちました。過去10年間で Cycles は、多数のアーティストやスタジオに使用される一人前のレンダラーになりました。私たちはこの十年間で多くのことを学び、順調でしたが、うまくいかなかったことや、レンダリングアルゴリズムとハードウェアの進化により、陳腐化したこともあります。
私たちはコアの Cycles レンダリングが大幅に改善されることに熱中しています。しかし、過去に行ったいくつかの決定により、パフォーマンス向上を阻害し、コードの保守も難しくなっていました。これらを解決するため、Sergey 氏と僕は Cycles X と名付けた研究プロジェクトを開始しました。アーキテクチャのリフレッシュと、次の10年間の準備が目的です。問題の一部のみを解決する応急処置や、最適化を見つけるのではなく、アーキテクチャ全体の見直しを行っています。
プロジェクト
プロジェクトの目標は大まかには以下の通りです。
将来の開発のためのアーキテクチャ改善ビューポートとバッチレンダリングのユーザビリティの改善モダン CPU と GPU でのパフォーマンス改善より先進的なレンダリングアルゴリズムの導入
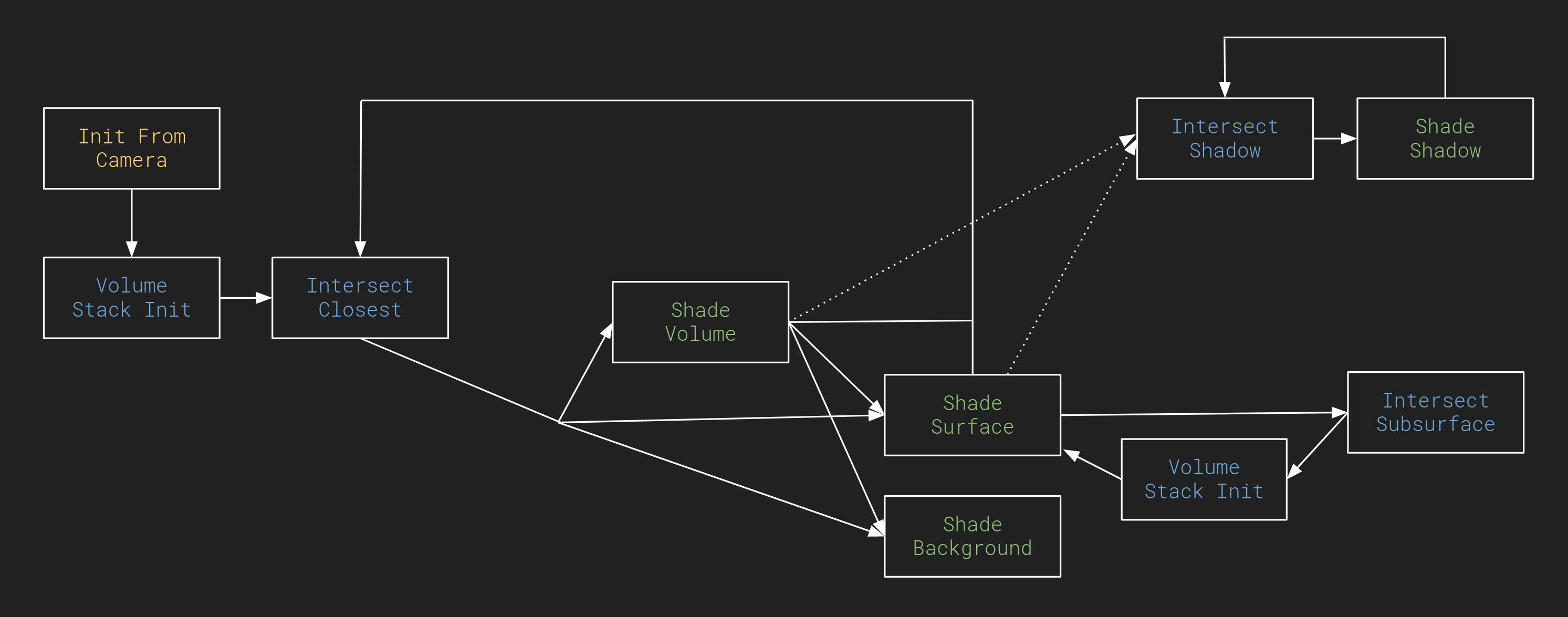
最初の目標は新しいアーキテクチャの確認でした。最終的に新しい GPU カーネルのプロトタイプと、ビューポートとバッチレンダー用の新しいスケジューリングアルゴリズムを実装しました。現在、私たちのベンチマークシーンのいくつかをレンダリングできる機能がようやく揃いました。
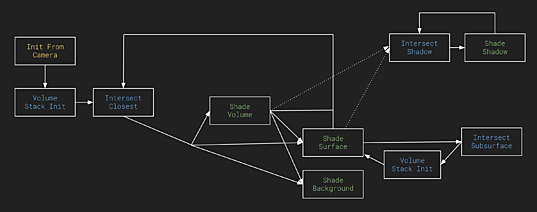 現在の Cycles X カーネルグラフ
今日は、最初のパフォーマンス結果を少しお見せし、Cycles の貢献者の皆さんとの共同作業を行うためにコードを公開しようと思います。開発者向けの新しいアーキテクチャの技術的プレゼンも利用可能で、コードは git.blender.org の cycles-x ブランチにあります。
やるべきことは多く、この成果が公式の Blender リリースの一部となるまで、少なくとも6か月はかかるとみています。
最初の成果
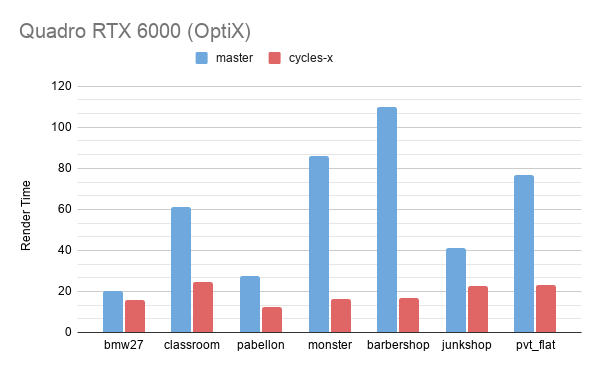
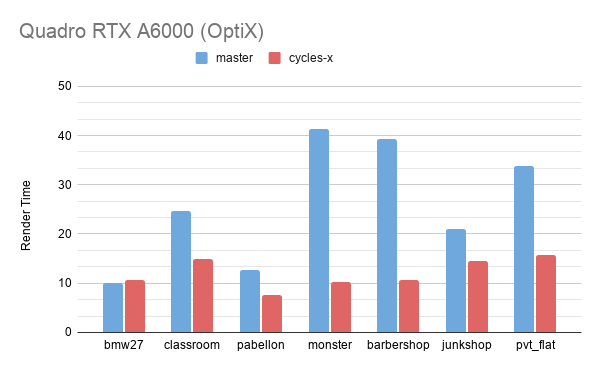
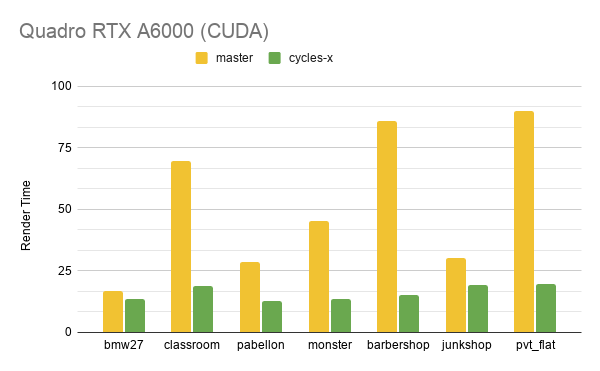
まず、ご存じのベンチマークシーンによる、GPU レンダリングの結果の抜粋です。これらのシーンは、未実装のボリュームレンダリングなどの機能を削除しています。
新しいアーキテクチャの作業を続けるに従い、数値は変わることをご承知ください。OptiX 対応は数日前に Patrick Mours 氏により追加されました。
多数の光のバウンスとシェーダーのある室内シーンが、最も大幅に改善しました。この場合、新しいカーネルが高い占有率とコヒーレンスを達成できます。
CPU レンダリングパフォーマンスは現時点では以前とほぼ同じですが、新しいアーキテクチャはここでも新しい可能性を広げています。
次に、ビューポートレンダリングの改善への取り組みについて。高速になったレンダリングカーネルが助けてくれますが、ビューポートをもっとインタラクティブする、スケジューリング、タイミング、表示メカニズムの改善方法を見つけました。
新しいビューポートは適応サンプリングとサンプリングのバッチ処理に対応しており、最初に少しのサンプリングが終われば、画像のクリーンアップが高速化されるようになります。
CPU ビューポートレンダリング
CPU ビューポートレンダリング+Open Image デノイザー
GPU ビューポートレンダリング
ビューポート適応サンプリング比較
未来の展望
今後数か月間、より多くの最適化のアイデアの挑戦と、欠けている機能の復活を行う予定です。機能が欠けているのは、新しいアーキテクチャで別のアプローチをとりたいからです。例えば、
ボリュームレンダリング:もっとモダンなアルゴリズムによるレイマーチングとライトサンプリングの実装を予定
シャドウキャッチャー:間接光の考慮が可能な、違うアルゴリズムに挑戦する予定
マルチデバイスレンダリング:タイルのない、より細かなロードバランシングを試す予定
その後、新しいアーキテクチャはパスガイディングのような、私たちが実験と、どれぐらい GPU フレンドリーにできるかを調査しているレンダリングアルゴリズムに、もっと簡単に適合できるでしょう
廃止
新しいアーキテクチャの一部として、以下のような機能をいくつか削除しました。
OpenCL レンダーカーネル。限定された Cycles の分割カーネル実装、ドライバのバグ、OpenCL 標準の行き詰まりのコンビネーションにより、保守が非常に難しくなりました。私たちは白紙の状態からスタートすることで、もっと大きな変更にのみ取り組むことができるようになります。
私たちは別の API の使用により、AMD と Intel の GPU で新しいカーネルを動作させる取り組みを行っています。これは最初のリリースには必要ではなく、その実装は、現存の物より高品質な基準に到達する必要があります。長期的には、すべてのメジャーな GPU ハードウェアベンダーへの対応は、重要な目標の一つとして存在し続けるでしょう。
分岐パストレーシング。現在これを時代遅れにする、必要な場所にサンプル数をもっと自動的に割り当てる、優れたサンプリングアルゴリズムに取り組んでいます。適合サンプリングと光源の重点サンプリングの改善がカギとなります。
NLM デノイザー。AI デノイジングアルゴリズム、特に OpenImageDenoise は全体的により優れた結果を生成しており、私たちはこれらに合わせてアーキテクチャとワークフローを最適化する予定です。
これらの機能は2.83と2.93 LTS リリースにて、利用可能なままにする予定です。
|
|